writing
How Arc Max achieves Magic, at a Cost
Apr 2024
AI features are everywhere, but their inner workings remain mysterious. When we see AI summaries and automatic tab organization, we imagine magic. Is that really the case?
I dug into Arc Max, a bundle of
5-Second Previews
5-Second Previews or hoverCards are instant summaries that appear when you hover over links in Arc.
Let’s run through an example for a Google search of ‘airbnb’:
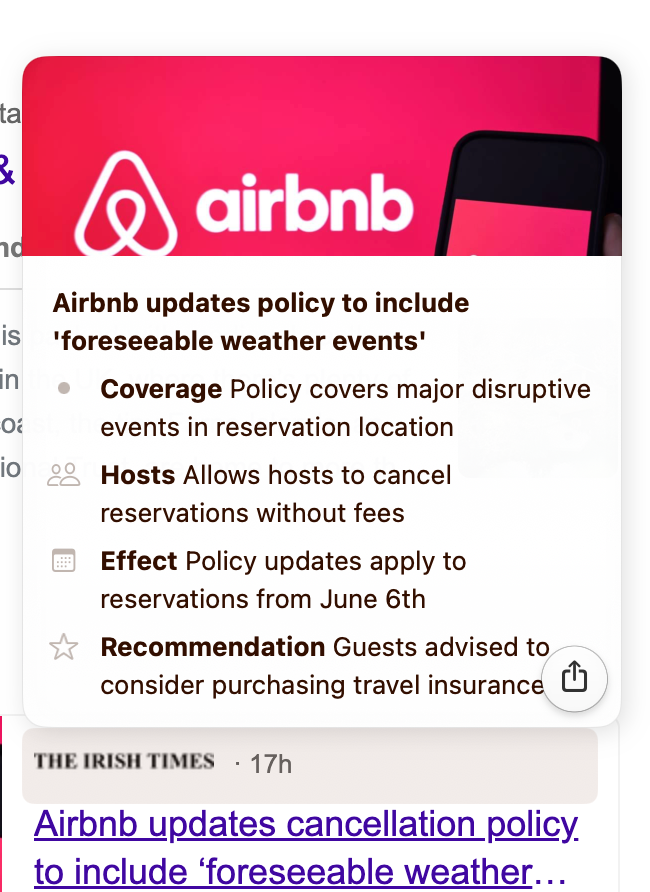
Hover over a link, and a card streams to you. The LLM prompt:
As a concise and helpful summarizer, create a glanceable "answer card" containing the most important information from the webpage.
Capture the tone, perspective and POV of the writer.
Provide a response using JSON, according to the `Response` schema:interface Response {
blocked: boolean // Does this page ask the user to enable Javascript or complete a security check before accessing the content?
userQuestion: string? // 1-word question to focus the rest of the answer card upon; based on user's search query: 'airbnb'
quickSummary: string? // 3-8 words the user is most likely to want to know, beyond the page's title. Provide a fact or opinion, not just a title.
details: Detail[] // 2-4 key points, solutions or items.
}
interface Detail {
label: string // e.g. "Price:", "Story:", "Solution 1:", "Highlights:", "Criticism:"
icon: string // Relevant SF Symbol systemName, e.g. "fork.knife"
info: string // 5-10 word summary, extremely concise
}WEBPAGE INFO:
<title>Host your home on Airbnb</title>
<url>https://www.airbnb.co.uk/host/homes</url>
<webpage>
[... markdown formatted webpage content ...]
</webpage>
Write responses (but not JSON keys) in English using markdown formatting.Typical response
{
"blocked": false,
"userQuestion": "cancellation policy",
"quickSummary": "Airbnb updates policy to include 'foreseeable weather events'",
"details": [
{
"label": "Coverage",
"icon": "umbrella",
"info": "Policy covers major disruptive events in reservation location"
},
{
"label": "Hosts",
"icon": "person.2",
"info": "Allows hosts to cancel reservations without fees"
},
{
"label": "Effect",
"icon": "calendar",
"info": "Policy updates apply to reservations from June 6th"
},
{
"label": "Recommendation",
"icon": "star",
"info": "Guests advised to consider purchasing travel insurance"
}
]
}Key techniques
- Structured Output: It specifies that the response should be provided in JSON format according to a defined schema in a Typescript interface.
- Contextual Prompting: The
userQuestionfield is included to guide thequickSummaryanddetailssections of the response. - Priority Ordering: The JSON keys are ordered based on relative-priority to ensure that when the card is streamed back, the card is produced top-to-bottom, left-to-right.
- Tag Block Context: Multi-line input often causes confusion in LLMs; hierarchy through tags (even though made up) works well - likely due to HTML in the pre-training data.
Tidy Tabs
By pressing a button, you can organise your open tabs into groups.
You are a meticulous expert organizer who follows instructions concisely.
I have some tabs! Please help me sort them into groups.I'll provide you with a list of tabs, with their IDs (e.g. google.com/3), their titles, and the tab they were opened from if applicable (e.g. ... google.com/0).
Think about the groupings of my browsing, and then choose a descriptive group name for each.Group based on keywords in common, domain, website purpose, and referring tab. If a tab has a unique keyword in common with tabs in a group, include it in that group. Use the unique keyword in the group name.
Some tabs may be in a group of their own, but you should try to find include each tab in a group if possible.For example, if these were my tabs:
```
google.com/0: nitehawk cinema - Google Search
amazon.com/0: Amazon: Amazing Deals on Home Goods, Gifts and More
google.com/1 toaster reviews wirecutter
toasttech.com/0 What you should look for in buying a toaster ... google.com/1
calendar.google.com/0 June 25 | Weekly View
pavilion.com/0: Barbie Movie | Pavilion Theater
```You would output:[
["google.com/0", "Movies"],
["amazon.com/0", "Toaster Shopping"],
["google.com/1", "Toaster Shopping"],
["toasttech.com/0", "Toaster Shopping"],
["calendar.google.com/0", "Calendar"],
["pavilion.com/0", "Movies"]
]Here are my tabs, in the format 'id: title':
[... faketab.com/0: some tab title ...]
Your array of group assignments, as valid JSON within a ```code block```:Key techniques
- Examples: Examples are by far the most effective way to guide output; they are a stepping stone to evaluations and fine-tuning as well.
- Nuance is king: Here we have a particularly nuanced example of tabs to group, it has:
- Different groups for the same domain (e.g. “Movies” and “Toaster Shopping”)
- One-item groups (e.g. “Calendar”)
- Subtle inferences (e.g. Amazon Home Goods is related to “Toaster Shopping”)
- “Words in your mouth”: You can often encourage LLMs to follow your instructions by starting the response for them, and in doing so you “put words in their mouth” and they continue the sentence.
Costs 3
Arc Max runs on fine-tuned GPT-3.5 4 models accessible via a Vercel-hosted, OpenAI-style chat endpoint. The cost of running these models is $3.00 / 1M input tokens and $6.00 / 1M output tokens for inference, which implies a cost per preview card of around $0.004 5.
With 170k Windows users, assuming a 5:1 Mac to Windows user split and the average user using hover cards 3 6 times a day, that amounts to about $350k per month in costs just for “5-Second Previews”; that a serious expense!
Footnotes
-
Arc is my daily driver and I’m a big fan of the product. Please don’t misconstrue this as either A) a criticism of the product, or B) a “leak” of company secrets. This information is part of the network traffic - no decompilation required - and I’d expect that The Browser Company would not see these prompts as their “secret sauce”. ↩
-
I discovered this by accident while performing an MitM on my own machine; simply record network traffic with wireshark and search for host connections to open-ai-chat-omega.vercel.app. You’ll find the prompts in the request body. ↩
-
These are very rough napkin estimates, there could be special deals with OpenAI/Vercel, and/or my estimates of usage are wildly inaccurate. ↩
-
Honestly, I am a little baffled why GPT-3.5 is being used here - many 7B open-source models would be more than enough for this task at a 30x cost reduction. Likely iteration speed is a factor. ↩
-
Around 1k input tokens and 200 output tokens. ↩
-
I use around 10 hover cards a day in bursts of up to 30 per day. I assume others are less likely to use hover cards - perhaps 3 per day on average. ↩