projects
Keyboard Expanse: On-Keyboard Gestures
May 2022
Keyboard Expanse is a subtle finger movement recogniser designed for the keyboard surface. No additional hardware is required, instead, it uses a single web camera common in consumer environments. Gestures are used to accomplish various computer commands, such as minimizing a window or selecting text at a sub-30ms latency.
Keyboard Expanse is designed to be personalized, offering users all degrees of flexibility they need using robust gesture specification and grammar.
Our results find gestures improve efficiency compared to mouse-only usage, and comparable performance to keyboard shortcuts while showing a rapid learning curve (achieving keyboard shortcut level performance in minutes) and low error rate (under of normal typing).
Introduction
Current ways of using a computer are often rooted in users adapting to the existing system – a particularly salient example being the “QWERTY” keyboard layout, residual from the days of mechanical typewriters. Keyboards are essential for efficient operation, and keyboard shortcuts are powerful tools for expediting common operations with a few keystrokes.
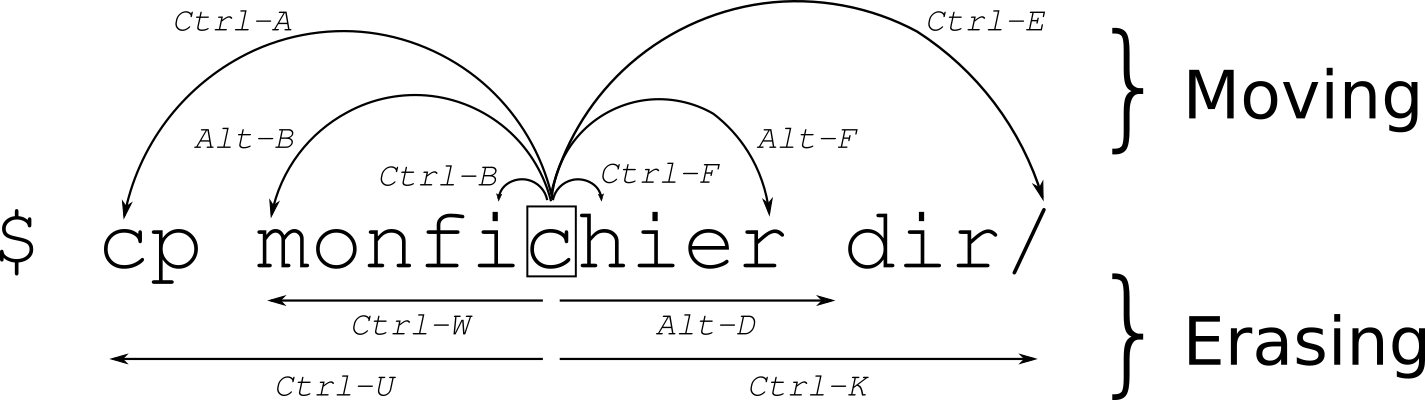
Keyboard Shortcut-based Movement, these shortcuts only work on Linux Command Line
However, these shortcuts are often limited by memorability – while powerful when leveraged, most keyboard shortcuts are un-intuitive and difficult to integrate into one’s existing workflow (for example see the useful ‘cheatsheet’). They, at times, require awkward control sequences and are not consistent over different operating systems; keyboard shortcuts on Windows systems don’t translate clearly over to macOS devices.
The alternative to keyboard shortcuts, and the one used by most due to its ease and simplicity, are menu operations using the mouse. However, switching back between the keyboard and mouse breaks a user from the flow of their work.
Thus, we propose Keyboard Expanse, a hand-tracking system to expand the scope of near-keyboard hand postures. Keyboard Expanse provides a cross-platform, configurable interface to blend discrete gestural commands with continuous tracking commands, in addition, the keyboard is used as a surrogate touchpad for desktop interactions. This system does not seek to replace the mouse or keyboard shortcuts; rather it is to augment the existing systems of interaction and enables individual users to configure their interactions to their comfort.
Keyboard Expanse is rooted in five core design considerations:
- Grounded Location: Interactions with Keyboard Expanse must remain grounded, not requiring raised hands that cause gestural fatigue.
- Subtle Events: Any discrete interaction should require no large, artificial movements required, such as 180-degree wrist rotations.
- No “wake”-command: The system should be constantly active and attempting to capture gestural commands. False interactions should be prevented by careful selection of gestures and localization of hands relative to the keyboard - similar to how trackpads are only in operation when directly used, not when palms are pressed against them. Together, this allows for keyboard-shortcut level speed.
- Concrete metaphors: Interactions should be related to real-world experiences. To go left you point left; to minimise you swipe the window away; to change the desktop you move along the keyboard.
- Works alongside Keyboard Shortcuts: Keyboard shortcuts still have a place in this system: Copy + Paste are both ubiquitous, and well-known and have no quick facsimile in gestural space.
System
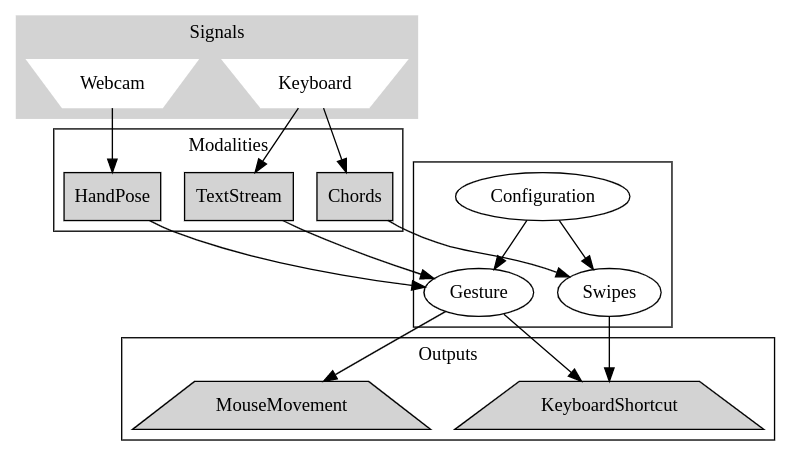
Simply put, our system executes computer commands based on how the user’s hands are configured. The main source of input is a video feed that has both hands in the frame on the keyboard. This viewpoint is constructed from either an external webcam or a mirror reflector on a laptop’s existing webcam. As the processing time of a particular frame of video is variable depending on the presence of hands in the image, this causes the video input to be captured at a variable sample rate. We artificially limit this to 30 FPS to allow for consistent frame rates and time-based outputs. This rate was determined from the average “loop” time of the entire processing pipeline on a Laptop CPU (11th Gen Intel i7-1165G7 (8) @ 4.7GHz) being sub-30ms. Reducing frame rate diminishes the tracking performance so the highest possible consistent frame rate is desirable. Consistency is required to support the assumption that the frame counter is a facsimile of time passed.
demonstrates the standard angle configuration for our system.

From this angle, the input is then processed through the MediaPipe Hand Landmark model (using Tensorflow on the CPU), which forms the basis for all camera-based gestures. For example, having the left hand clenched and tapping the right index up will trigger a new window to be opened. The system also has a basic implementation of keyboard input listening – swiping across the QWERTY row of the keyboard from left to right will trigger a left swipe on the computer to change the desktop. More system details and configurations are discussed in the following sections.
Sliding Window Chords
Keyboard Expanse takes in keyboard input via a cross-platform keyboard interception.
By intercepting all keyboard strokes, and relaying those that do not form a gesture, we allow for “chord” detection, e.g. multiple key presses within the same window of time.

By storing insertion time alongside the value, we can expire old values on insertion or update insertion time for existing values. Together this forms a traditional sliding window operation.
We then detect swipes by distinctive key sequences that do not occur on standard input - for instance e+r+t which is uncommon on typing sessions.
Landmarks to discrete hand positions
The output from the MediaPipe model is the landmark positions which denote accurately denote the X, and Y positions from the camera viewpoint of particular hand landmarks such as the fingertips or wrist.

This alone is insufficient for several typical use cases, firstly we need to extract a few key features that would otherwise be lost:
- Palm Orientation: Is the hand facing palm towards the camera or away? This piece of information allows for the relative thumb position (is it extended or clenched) to be calculated by comparison to the base position with a single comparison (thumb x < base x or vice versa).
- Handness: Left Hand / Right Hand is needed to allow “Asymmetrical” gestures. MediaPipe does not provide this directly, instead classifying each hand as a separate instance. This allows for multiple people to be in the frame and interact. For our use case, however, we only need 2 hands as this is an individual-only device. To extract this information we run a secondary model to classify individual hand instances as “left” or “right” hand, extract the two most confident hands and sort them to create a unique, consistent order.
Gesture Taxonomy
When constructing this system, we felt the need to have a standard way to refer to gestures visible on the keyboard. This “Gesture Taxonomy” as we came to refer to it allows for a subset of hand pose gestures easily performable on the keyboard to be defined unambiguously for detection and configuration.
Ultimately we broke down each finger position into 3 different position classifications - “Up”, “Resting”, and “Clenched” - these three poses can be inferred from the landmark information. These classifications intuitively map to our common understanding, but technically have specific meanings in implementation:
- A finger is “Up” if it is raised above the ‘baseline’ landmark for that finger is above (in the y-axis) by a per finger configured threshold.
- Otherwise, a finger is “Clenched” if the first joint of the finger is below the fingertip.
- By default, a finger is “Resting”.
To exemplify this consider the index finger, the index finger is composed of 4 landmarks: INDEX_TIP, INDEX_DIP, INDEX_PIP, and INDEX_MCP. The configured baseline is the RING_TIP. When the distance between INDEX_TIP - RING_TIP is < -0.15 or equivalently RING_TIP - INDEX_TIP > 0.15, then the INDEX_TIP is significantly above the baseline RING_TIP and is classified as “Up”.
This system of baselines is not perfect for all gestures - namely attempting to raise the ring finger and index finger together may cause the index finger to not be considered “Up”. Fortunately, empirically speaking, this is not often an issue due to the raised viewpoint creating a significant difference between fingertips during a parallel raise that is not present during resting position.
An alternative approach would be to take an average of finger positions, under the assumption that the fingers are normally at rest. This requires localization of the fingers to the keyboard which is discussed below, to ensure that when the fingers are away from the keyboard the “baseline” position isn’t compromised.

“Flat Rock” mirrored gesture
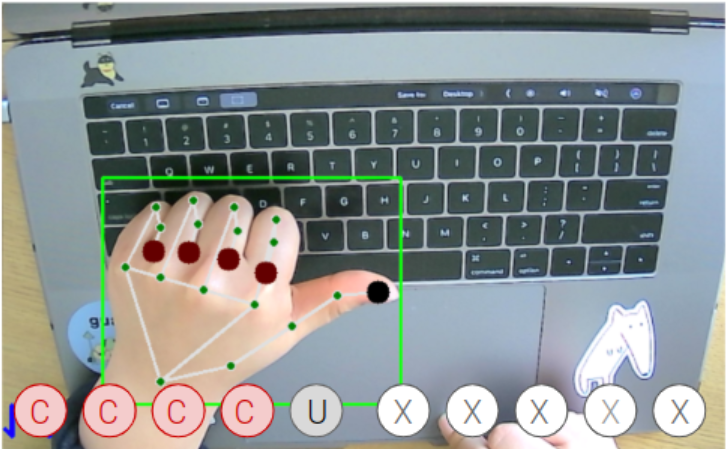
Left Thumb asymmetrical gesture
The sheer number of possible gestures that can be encoded by this system is notable, but it is worthwhile to consider the ease of some of these combinations.
Consider any gesture combination that requires a raised finger next to a clenched one, this tends to be uncomfortable to sustain, which leads to us eliminating their usage for gestures - this simple restriction results in only 6,724 gestures (25.62%) of the taxonomy.
In addition, the ring finger and middle finger tend to move in parallel for comfort. This restriction reduces us to 1,156 possible gestures (4.4%) of the taxonomy.
This much smaller set gives a list of “reasonable” gestures. For instance, we have randomly sampled from this set to demonstrate feasibility:
- RCCRC URCCR
- CRRUC URUUU
- RUUUU UURRC
- RUUUC URRRC
However, we primarily consider only gestures with concrete metaphors for real-world usage rather than “learnable” gestures that are, at best, on par with keyboard shortcuts. What constitutes a good concrete metaphor can be a creative process, but often we can take advantage of existing gestures that occur in the real world: Such as “pointing” and “snipping”.
We can see the utility of the gesture taxonomy by taking a look at the configuration for a Keyboard Expanse gesture set.
Here we see a mixture of one-handed symmetrical gestures (Flat Rock Star), two-handed asymmetrical gestures (Left Thumb Out), one-handed asymmetrical gestures (Left Three Up), and symmetrical two-handed gestures (Double L). Each gesture is expressed with the same grammar, the notable change is X which marks an “any” position.
hands:
- name: "Flat Rock Star"
position:
mirror: "XRCCR"
action: "ChangeWindow"
- name: "Left Thumb Out"
position:
left: "UCCCC"
right: "CCCCC"
action: "MoveRight"
- name: "Left Three Up"
position:
left: "CRRRU"
right: "XXXXX"
action: "JumpUp"
- name: "Double L"
position:
left: "URCCC"
right: "URCCC"
action: "SelectAll"Tap and Touch
Certain gestures work better if there is a motion-based component to them. Repetitive commands that produce discrete actions, such as ‘minimizing’ were found to be more naturally expressed by the transition between two gestural states. For instance, the thumb is extended and clenched.
We express such transitions by considering the “finger state” - the particular finger classification at any instance - and the “gesture state” - the particular gesture (or gestures) that match this finger state - as nodes within a state machine.
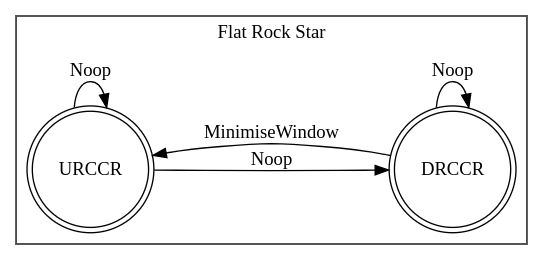
“Flat Rock Star” State Machine Example. The “Flat Rock Star” gesture comprises two mirrored states (the other hand is omitted for simplicity). We can see both the finger states (nodes), the “Gestures” (boxes), and the “Actions”
This allows for actions to occur on gesture start, during a gesture (at “loop” rate), on finger transition (if the gesture applies to more than one finger state), or on gesture ends.
Occasionally the ending finger state we want to be anything, this occurs most frequently in “touch” gestures. Where the key state is when two finger points are sufficiently close to triggering the new “gesture”.
To allow for this we “store” actions to be applied on the gesture ends, and then check for stored actions on the existing transition between any two gestures.
For instance, the Index Finger Touch gesture only applies to the separation of fingers, not when they first meet.
This allows for the detection of touch duration (long press vs short tap).
hands:
- name: "Index Finger Touch"
tap:
left: "XOXXX"
right: "XOXXX"
threshold: .05
action: "FindAndReplace"Transition Delay Table
The other key concept that applies the concept of finger positions as a state machine is the transition delay table.
Certain gestures should not occur in sequence or likely occur only due to misclassification, by allowing for a gesture to trigger an “action” if and only if a sufficient time delay has occurred between the start of that gesture and this new gesture we gain fine control over the responsiveness.
This also allows for time-based rate-limiting of actions by considering the self-loop as a transition that can be delayed as well.
Generally speaking, we don’t tend to apply a delay for self-loops as it frequently creates apparent false negatives. Gestures frequently occur in sub 500ms speeds; for instance, flicking.
Keyboard Localization
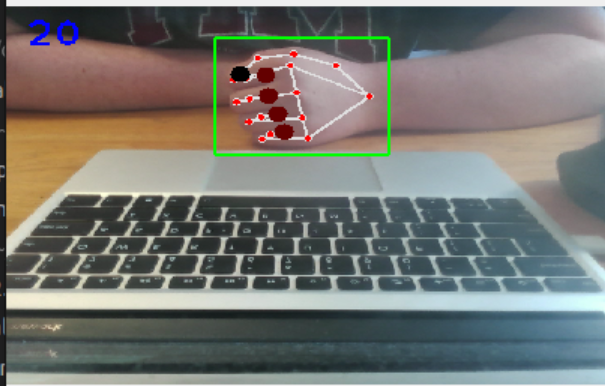
False Positive for “Peace” sign caused by rotation of the upward resting hand.
Localizing the hand position to the keyboard was an area of study during the project. The goal was to 1) increase the variety of gestures by allowing relative locations e.g. on the trackpad, the edges of the keyboard; 2) to decrease the false positives that occurred when the hands were away from the keyboard and at a dramatically different orientation (see Resting False Positive); and 3) improve the “Up” detection with a consistent baseline.
This was processed in a seven-step pipeline, aiming to extract from edge information, the surface of the keyboard.

V channel from HSV form of the input image with colour range masking.

Adaptive Threshold Gaussian Thresholding

Canny Edge detection is applied on this binary surface

Contours are extracted from edges by closing any similar loops

Selects a single contour using a variety of criteria.

Weighted Mean Rectangle
This algorithm is very similar to existing attempts at “paper” detection for photo-scanning. The only notable novelty is in steps 1, 5, and 6.
In Step 1, where the initial image is preprocessed for thresholding, we apply colour range subtraction. To aid the edge detector with isolating the keyboard from the table surface we use colour information rather than just edge information to apply a mask to the image removing any potential false edges.
For instance “wooden surfaces” have a distinctive colour range that is not present on keyboards - ([0, 92, 39], [178, 216, 255]).
This allows for some colour awareness even with the single channel processing early in the pipeline.
In Step 5, we apply some criteria to select a single contour from a collection of candidates:
- Area must compose of at least 50% of the image.
- This prevents other rectangular objects such as keys, or the trackpad from being selected as the computer surface.
- Contour must have an approximate (within 3% error rate) convex hull polynomial form with 4-6 points.
- This ensures that our contour is sufficiently rectangular while allowing for small deviations (e.g. power cables or occluded edges).
To standardise this into a trapezium form, we merge the nearest points recursively until we get a four-point shape for example.
The final Step 6 allows the process of keyboard discovery to be iterative. By applying a weighted mean to the surface detection we allow for occasional misclassifications caused by lighting variations while still discovering the mean keyboard surface.
The result is variable at this stage (and is an area for further research) - sometimes the detection works perfectly, and sometimes reflections present on the surface create color ranges that are close enough to the grey laptop surface to be misclassified.
It seems likely that applying some additional knowledge of the keyboard shape (starting at the bottom of the screen) or the presence of keys dominating the bounding box would improve this result.

Highlighted surfaces on the annotated image demonstrates the ability to locate the hand on “known” keyboard surfaces

Projection mapping of the keyboard surface - allows for fine-tuned detection of finger position relative to keyboard position. For instance to detect which key was pressed.
Evaluation
There were multiple rounds of user studies. The first two rounds of user studies, for earlier implementations of our system, were based on the same task of opening a particular website, searching for something, and selecting the option. The first user study was heavily focused on mouse control and the second was a combination of mouse control and keyboard gesture. These early user studies prompted the pivot detailed in the Adjustments and Pivot section.
Our final series of user studies, with the complete implementation of our system, is threefold – we conducted these user studies with around six individuals each. All three studies yielded interesting themes about our system’s learning curve, sensitivity, and general usability.
”Find the Window”
The first user study was focused on minimizing a series of ten windows on a computer desktop through a comparison analysis; they started using the mouse only, learning the keyboard command to minimize on the testing device and using keyboard only, using our gesture, and using their preferred method. The results of the study are shown below, with the black lines representing the standard deviation.
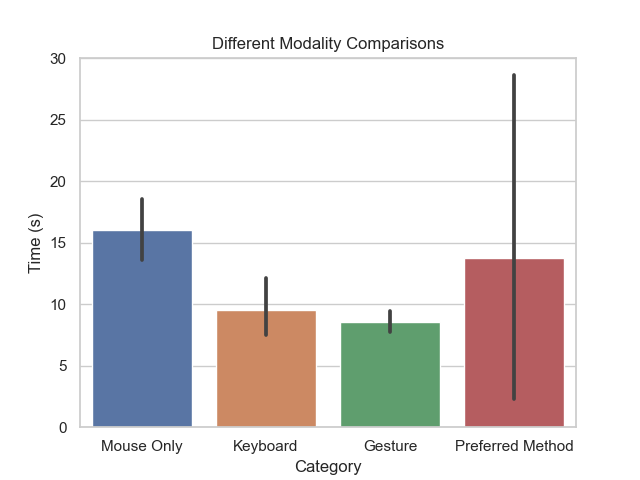
Find The Window
Overall, this showed that we performed favorably against the mouse only and competitively against the keyboard shortcut, Cmd + M or Ctrl + M. None of our users were aware of the keyboard shortcut for minimize before the user study, illustrating how obscure most keyboard shortcuts are.
This study also revealed that our system of gestures does have a learning curve (see Plot of Learning Curve Timings) and often requires a few trials before users reach a lower bound of speed. However, the users found gestures much more memorable and easy to perform than keyboard shortcuts.
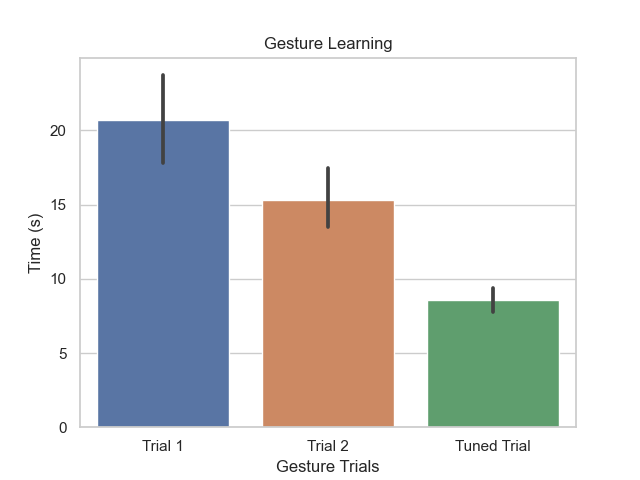
Learning Curve over trials, trials were separated by approximately 1 minute and lasted for 30 seconds. No configuration changes were made for the first two trials, the final trial had a global configuration change.
”Selection and Navigation”
Similar to the first user study, our second user study comprised selecting a long link with our selection gesture, copying it, opening a new window, and pasting it to navigate to the final link. Users had two trials with the gesture system, and we also measured how long the task took with their preferred method and noted what methods they employed.
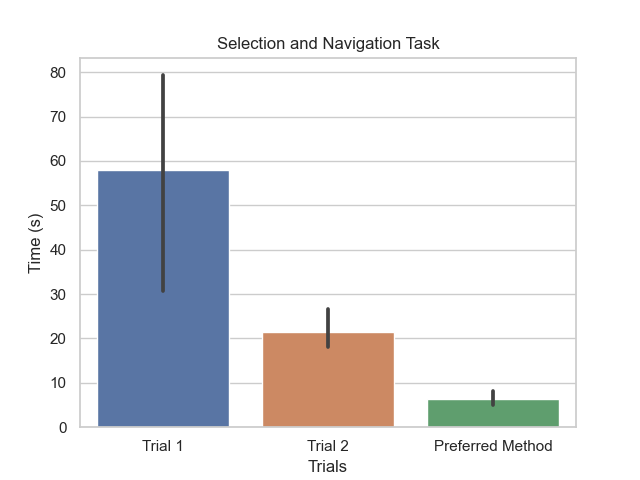
Select and Navigation Task Results
The results of this study echoed learning curve findings from the “Find the Window” study – users did significantly better with the second trial of the system – and also illustrated that there are not always useful applications of gestures. For more context, users selected and navigated through the link with the following configuration, which would trigger a right or left arrow depending on the direction pointed. They then proceeded to open a new window with another gestural command of the upwards right index tap. Across the users, each of them had different preferred methods – some employed keyboard shortcuts consecutively, while others preferred using the trackpad. One user whose personal device is a Windows computer used Ctrl + C before being reminded that he was on a macOS device. Adding the pinky would trigger the addition of a Shift key, which allows for the highlighting of text.

An example of the right hand thumb pointing left with the pinky, which would trigger selection from right to left
Unfortunately, users with high trial times had such high times because they would get stuck overshooting their selection and continue to have difficulty correcting. Our system would also sometimes accidentally deselect the entire selection before users could copy the link. While this study was constrained to very isolated methods and tasks, it ultimately shed light on how our system is too sensitive and could drastically lower the convenience of gesture-based commands. It also emphasized how some tasks focused on precision are not the best fit for our system – similar to our issues with mouse control that we discuss in Challenges, Adjustments, and Pivots. This was especially salient given the short time to complete the task using preferred methods.
”False Positives”
Finally, our last user study was a qualitative analysis – we had users complete a typing test with our system on to see what commands might be accidentally flagged.
We ran a total of five trials, with the first trial triggering no commands and the last four triggering one instance of the Index Finger Touch with each trial lasting a minute.
The low false positive rate can be attributed to our gesture taxonomy – the default pose for our system is the hands interacting with the keyboard, with all fingers “resting” and the thumb stretched out to “up.”
It then makes sense that the touch gestures would be the most sensitive to triggering false positives, especially for the index fingers, as they are one of the most active digits covering the most distance given the configuration of the QWERTY keyboard and the structure of our hands.
Challenges, Adjustments, and Pivots
The biggest lesson from this project was about usability: we were ambitious that we could build an alternative to keyboard shortcuts.
We had maintained a clear vision for how keyboard usage would completely change and an individual could navigate their system beautifully all from the comfort of the hands on the keyboard. However, as the project progressed, we realized that users are inherently used to the standard keyboard, some small number of keyboard shortcuts, and the mouse.
Our interesting failures with the mouse implementation further emphasized to us that we shouldn’t seek to replace any existing system but we should rather ideate on how we could best augment with the power of multimodal features. We narrowed our gestural capabilities to what worked, and users responded well. One participant immediately brainstormed how gestures would help when she was preparing food but didn’t want to touch her keyboard; another mentioned switching between windows while finishing his final term papers. More specifics on the developments that contributed to this realization are below.
Eye Gaze and Mouse Control to Hand Tracking Only
Our project was originally based on combining subtle keyboard gestures with eye tracking. We felt that eye tracking could be a powerful modality to combine with keyboard gestures – eye tracking could help overcome the limitations of a top-down viewpoint used for hand gestures, and the gestural component could aid with the limited spatial accuracy of eye tracking. This application could be especially powerful when considering applications related to contexts, such as context switching to another tab or screen.
However, as the implementation of our system began, modern hand-tracking software was much more powerful than anticipated; MediaPipe offered quite a rigorous tracking of 21 landmarks, for the joints on the hands, and we were able to build a powerful system off of hand tracking alone. On the flip side, we were concerned about the user fatigue that eye tracking might introduce, and we wanted to maintain the design considerations of the system.
The decision to cut out eye tracking and focus more on keyboard gestures was also influenced by our mouse control implementation. This was one of our most notable failures – we implemented a basic mouse control feature with tracking based on the tip of the index finger, of landmark 8, but were unable to scale the sensitivity of the mouse control without needing more movement from the hand. We achieved poor granularity compared to mouse or trackpad control, and the range of motion needed would violate the grounded control of our system. One approach we did take before reconsidering was to create a scaled bounding box smaller than the camera space that would allow for more sensitivity with less index finger movement, but this method failed to provide the precision to hit smaller target objects.
We had originally considered utilizing eye tracking to assist with the mouse control, but we decided to focus on building out a powerful yet flexible gesture taxonomy instead given the limitations of both eye tracking software and mouse control. Eye gaze caused additional problems because the two were ultimately disjoint – users are often multitasking and glancing at multiple locations on the screen, so there was no clear way to solve the open mic issue for eye data.
Our final motivation was the need for two camera perspectives. Keyboard Expanse uses one viewpoint focused on the hands. This is generally well-received and even though it is a constant recording (although not stored) users found the approach not to invade their privacy. In comparison eye tracking inherently requires a facial viewpoint which made people uncomfortable.
Attempting to support two viewpoints (and two cameras), while possible, also adds setup burden on the user. No longer can we use likely preexisting equipment alone.
Sensitivity Calibrations
An additional interesting issue we faced with our system was its overall success with latency; while this is inherently a great feature, it triggered many issues with false positives and double-clicking of particular gestures. The implementation of our system, through the gesture taxonomy, allowed our system to perform competitively with keyboard shortcuts, so we wanted to maintain the overall sensitivity but add some friction when needed.
First, we imposed gesture-specific delays onto our system via the transition delay table, which was discussed in our system overview. We considered decreasing the frame rate of our input, such as only considering every other frame, but we didn’t want to compromise the overall success of the gesture recognition. Thus, we instead considered gesture transitions as a state machine instead of compromising our input data.
Another calibration we implemented to help with the system’s sensitivity was a decorator function that ensured gestures could only be called every x seconds. We varied this from a scale of every 0.5 seconds to every 5 seconds, depending on the gesture. This was a particularly important feature for commands we want to prevent duplicates of, such as opening or closing windows.